How the algorithm works¶
In this tutorial, we give a brief overview of the algorithm behind 21cmSense, to give a more intuitive/physical understanding of what it is doing. In this tutorial, using the code itself takes a backseat in favour of the conceptual understanding.
To make this nice and clear, we follow the outline in Liu & Shaw (2020), which provides a series of steps that roughly align with how 21cmSense works. The following is the quoted summary:
Given the antenna locations of an interferometer, compute the \(uv\) coordinates of all baselines.
Segement a \(uv\) plane into discrete cells, each of which has roughly the same width as \(\tilde{A}_p\) [i.e. the Fourier-Transform of the beam]. Roughly speaking, this width is the inverse of the instantaneous field of view of an antenna. Define a three-dimensional \(uv\eta\) space, extending the \(uv\) plane into a third dimension of Fourier space. Each cell in this dimension should have an extent of 1/\(B\), where \(B\) is the frequency bandwidth of the observation.
Simulate the movement of baselines through the \(uv\) cells over a sidereal day of observations (or over however much time the telescope is being operated per sidereal day). Record how much time \(t_u\) each baseline spends in each \(uv\) cell.
Assuming a roughly constant noise contribution across frequency channels, the uncertainty (standard deviation ) from measurement noise for a given \(uv\eta\) cell is given by
where
and \(T_\mathrm{sys}\) is the system temperature, which is the sum of the sky brightness temperature and the reciever temperature. This is the uncertainty for one baseline. If multiple baselines spend time in a given \(uv\) cell, the integration times of each baseline must be added together before being inserted in the above equation.
Divide the uncertainty computed above by the total number of sidereal days \(t_{\rm days}\) of observation. Note that the standard deviation scales \(t_{\rm days}^{-1}\) rather than \(t_{\rm days}^{-1/2}\) because visibility measurements repeat every day and thus can be coherently averaged prior to the squaring step of forming a power spectrum.
Associate each \(uv\eta\) cell with its location in \(\mathbf{k}\) space using
For high signal-to-noise measurements it is necessary to account for cosmic variance which contributes a standard deviation of \(P(\mathbf{k})\) (i.e. the cosmological signal itself) to every \(uv\eta\) cell. This is added to the instrumental uncertainty.
Assuming that different cells in the 3D \(\mathbf{k}\) space are averaged together with an inverse variance weighting to obtain \(P(k_\perp, k_{||})\) or \(P(k)\), the corresponding errors can be combined in inverse quadrature. In other words, if \(\epsilon(\mathbf{k})\) is the standard deviation for a \(\mathbf{k}\)-space cell, then the final averaged error bars are given by \(1/\sqrt{\sum \epsilon^{-2}}\), where the sum is over all the \(\mathbf{k}\)-space cells that contribute to a particular bin in \((k_\perp, k_{||})\) or \(k\).
OK, so let’s go through each step in turn, and try to visualise it with 21cmSense, and understand the “why”.
Imports and Setup¶
[1]:
import matplotlib.pyplot as plt
import py21cmsense as p21s
%matplotlib inline
import numpy as np
from astropy import units
from astropy.cosmology.units import littleh
1. Compute \(uv\) coordinates¶
The important thing to remember here is that the \(uv\) coordinates of the baselines are frequency-dependent. For a tracking telescope (where the phase centre changes over time so that it keeps pointing at the same source in the sky), they also depend on time (i.e. the baselines “look different” to the source as it moves overhead).
Let’s take a simple HERA-like telescope as our model. We can create such an array with 21cmSense:
[2]:
hera_layout = p21s.antpos.hera(
hex_num=11, # number of antennas along a side
split_core=True,
)
[3]:
plt.figure(figsize=(7, 7))
plt.scatter(hera_layout[:, 0], hera_layout[:, 1]);
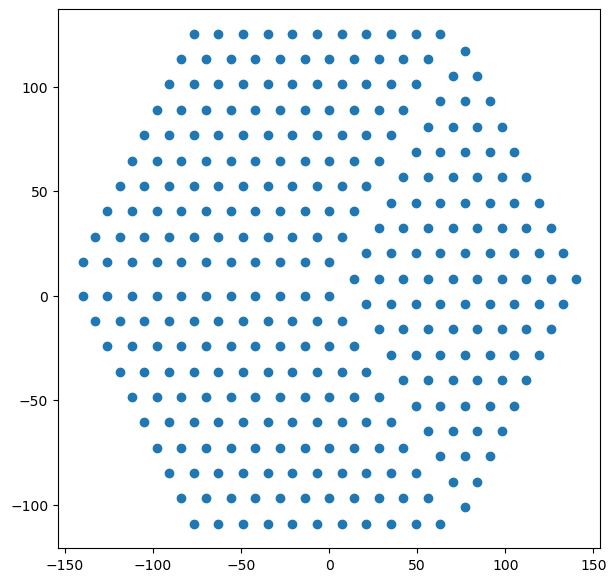
So far, we have the antennas, but not the \(uv\) positions. We could of course compute them from the array, but let’s use the in-built functionality of 21cmSense to do this.
The way to do it is to create an Observatory object, but to do this, we must also specify some extra information about the antennas themselves, in particular, their beam.
We won’t actually use the beam to do anything until the next step (2), but let’s go ahead and define one. Note that 21cmSense doesn’t do anything very interesting with the beam (you’ll notice that none of the steps use the exact beam shape per se, just bulk properties of it). We’ll use an in-built Gaussian primary beam for each baseline, that has a width that depends on the frequency:
[4]:
beam = p21s.beam.GaussianBeam(
frequency=150.0 * units.MHz, # just a reference frequency
dish_size=14 * units.m,
)
With that, we can construct the observatory:
[5]:
hera = p21s.Observatory(
antpos=hera_layout, beam=beam, latitude=0.536189 * units.radian, Trcv=100 * units.K
)
With that, we can determine the baseline lengths themselves:
[6]:
plt.figure(figsize=(7, 7))
plt.scatter(hera.baselines_metres[..., 0].flatten(), hera.baselines_metres[..., 1].flatten());
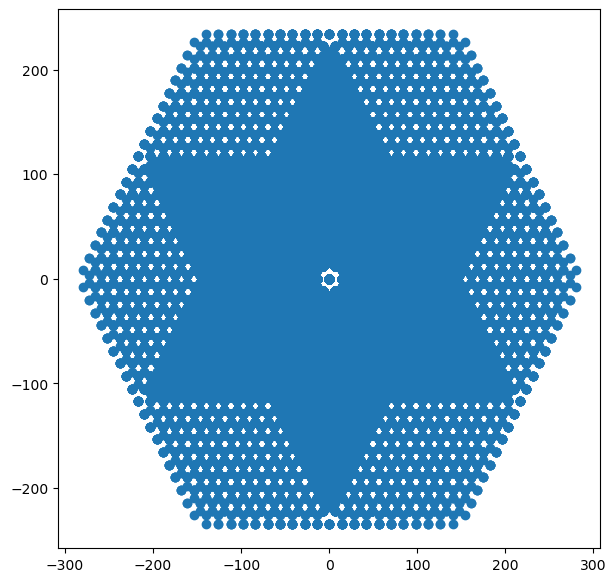
Since HERA has a lot of redundant baselines, it’s helpful to visualise how many baselines actually sit at each of these locations:
[7]:
red_groups = hera.get_redundant_baselines()
red_grp_coords = hera.baseline_coords_from_groups(red_groups)
weights = hera.baseline_weights_from_groups(red_groups)
finding redundancies: 100%|██████████| 319/319 [00:00<00:00, 1417.00ants/s]
[8]:
plt.figure(figsize=(9, 7))
plt.scatter(red_grp_coords[:, 0], red_grp_coords[:, 1], c=weights)
plt.colorbar();
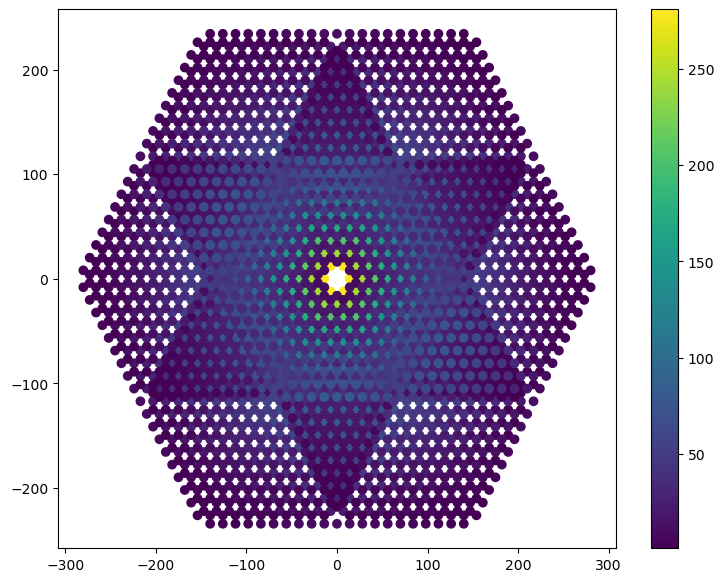
How many redundant groups are there?
[9]:
print(len(red_groups))
3002
Compared to how many baselines?
[10]:
len(hera.antpos) ** 2 - len(hera.antpos)
[10]:
102080
Note that we still haven’t actually computed the \(uv\) coordinates of all the baselines, and we won’t here because it’s frequency and time dependent. We’ll get to that in a later step.
2. Construct a \(uv\) grid¶
Why do we have to construct a \(uv\) grid? Why not just use the actual \(uv\) values of each baseline directly?
The simple answer is that the cosmological power spectrum is naturally defined as a function of spatial wavenumber \(k\) (which is the Fourier dual of comoving distance, \(x\)), and \(k_{\perp}\) is directly proportional to \(uv\), while \(k_{||}\) is directly proportional to \(\eta\) (the Fourier dual of frequency). Thus, the cosmological power spectrum would be naturally defined by the Fourier transform of a particular baseline, sitting at some \(uv\), over frequency, but only if that baseline stayed at the same :math:`uv` coordinate at all frequencies. This is not true, and so we have to have some way of defining what we expect the measurement to be at a particular \(uv\) across frequency. This must involve something like binning (or interpolation).
Why does the recipe specify that the \(uv\) grid should have cells with “roughly” the same width as \(\tilde{A}_p\)? Well, think about the visibility equation:
Ignoring subtleties of sky curvature and the horizon, this is essentially a Fourier transform, so that the convolution theorem applies:
This implies that the antenna “sees” in the \(uv\)-plane not just at its exact \(uv\) position, but a weighted sum of inputs, equivalent to \(\tilde{A}(\mathbf{u})\). Given that \(A(r)\) is typically a compact(ish) dome-like (Gaussianish) function, \(\tilde{A}(\mathbf{u})\) should also be one, with width inversely proportional to the beam width.
Now, imagine we create a \(uv\) grid where the cells are much smaller than the “width” of \(\tilde{A}_p\). Then each baseline really “sees” stuff from a number of cells, with different weight. Not only does this mean that evaluating the amount of noise in each cell becomes more difficult, it also means that the noise value in one cell becomes correlated with the surrounding cells (since the same baseline contributes to evaluating each of them). This makes all the calculations harder.
On the other hand, if the \(uv\) grid has cells that are much larger than the width of \(\tilde{A}_p\), we lose resolution. Cells that are close to the width of \(\tilde{A}_p\) ensure that correlations between neighbouring cells are minimal (and thus we ignore them…) and we get the maximum resolution that we can achieve.
21cmSense calculates this width for us in units of wavelength (nominally defined at the reference frequency, which we defined as part of the GaussianBeam):
[11]:
beam.uv_resolution
[11]:
7.004845999161192
And it also generates a \(uv\) grid:
[12]:
ugrid = hera.ugrid()
[13]:
ugrid.min(), ugrid.shape
[13]:
(-140.09691998322387, (41,))
The recipe calls for a three-dimensional grid, \(uv\eta\). To define the \(\eta\) part of the grid, we require information about the bandwidth of the observation. Note that this bandwidth is that bandwidth going into a particular power spectrum estimation, not necessarily the full bandwidth of the instrument itself. Typically the bandwidth will be less than about 20 MHz, because of the concern of the Lightcone Effect.
Since most instruments have regularly spaced frequency channels, the \(\eta\) grid is effectively the Fourier dual of the frequency channels.
To obtain this, we need more than just an Obervatory, we need an Observation (i.e. a strategy with which to observe with the observatory…). We set this up now, noting that there are quite a few more parameters that go into defining an Observation that we’re ignoring here (they have sensible defaults, and we’ll see what they do later):
[14]:
observation = p21s.Observation(
observatory=hera,
n_channels=80,
bandwidth=8 * units.MHz,
)
We can now get the \(\eta\) grid:
[15]:
observation.eta
[15]:
3. Simulate movement of baselines¶
Simulate the movement of baselines through the \(uv\) cells over a sidereal day of observations (or over however much time the telescope is being operated per sidereal day). Record how much time \(t_u\) each baseline spends in each \(uv\) cell.
There’s some subtlety here.
The main point is that within a certain “small” amount of time, the telescope is essentially measuring the same sky over and over again for each snapshot visibility it measures. The amount of time it integrates for a particular visibility snapshot is called the integration time, and since the thermal noise on the visibility is averaged over all this time, the total noise goes down linearly with this amount of time.
But who’s to say we couldn’t have joined the next snapshot into this one? If it’s essentially the same sky, we could average it together as well. The subtlety comes about because in detail it depends on if you’re tracking a point on the sky, or letting it drift overhead. For a drift-scan telescope (like HERA) the amount of time you could average together depends on the size of the beam: if the sky has rotated enough that everything that was in the beam is now out of it, you’re essentially taking
an independent observation, and you can’t average that in visibility space (only in power spectrum space). By default, 21cmSense will assume that you’d average together observations for as long as it takes to get throug the FWHM of the beam:
[16]:
beam.fwhm * 180 / np.pi
[16]:
[17]:
observation.lst_bin_size
[17]:
Of course, you can change this manually if you want to!
But it gets a little more complicated. Within that time-window, while you’re essentially seeing the same thing, you’re not actually measuring the same thing with a particular baseline. Averaging the values for that baseline together over the time will cause the visibility to decohere. Instead, you can think about tracking the observation within that time window, so that the sky seems to stay constant, but the projected baseline lengths change. This way, the same point on the \(uv\) grid will always get the same measurement (at least, roughly), but the baselines contributing to this \(uv\) cell will change.
This is why we have to measure how much time each baseline spends in each \(uv\) cell – they move with time. Ideally, we can average down the noise linearly with the amount of total time spent by all baselines in a particular cell. You can also specify that you don’t want to average the visibilities together this way (instead you can just average power spectra over time), but lets for now assume the coherent assumption:
[18]:
observation = observation.clone(coherent=True, integration_time=60 * units.s)
We can generate a map of how many baselines were in each \(uv\) cell over a single observation duration:
[19]:
observation.uv_coverage;
finding redundancies: 100%|██████████| 319/319 [00:00<00:00, 2259.28ants/s]
gridding baselines: 100%|██████████| 3002/3002 [00:00<00:00, 9761.32baselines/s]
[20]:
plt.imshow(observation.uv_coverage, extent=(observation.ugrid.min(), observation.ugrid.max()) * 2)
ax = plt.colorbar()
ax.set_label("Number of snapshots per uv cell")
plt.xlabel("u [wavelengths]")
plt.ylabel("v [wavelengths]");
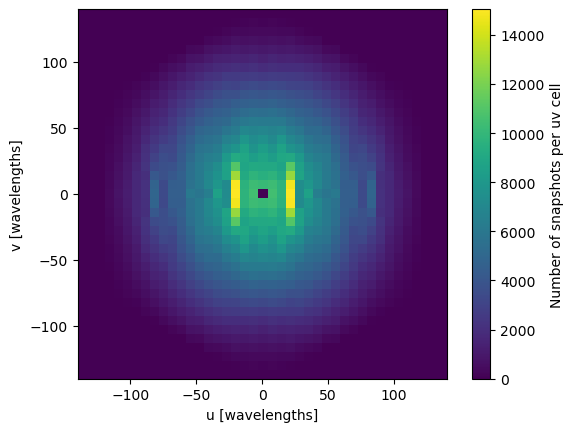
4. Obtain Noise Per Day Per Cell¶
Now that we know how much total time is spent by baselines per \(uv\)-cell, we can calculate the thermal noise on a power spectrum estimate in that cell. Note that the thermal noise is constant with respect to \(\eta\).
To do this, we use a Sensitivity class. These classes do sensitivity calculations of various output statistics that might be computed by an Observation. In this case, we are interested in the PowerSpectrum sensitivity:
[21]:
sensitivity = p21s.PowerSpectrum(observation=observation)
This class has a simple method that calculates the thermal noise, according the equation given as part of this step. The key here is that \(T_{\rm sys}\) is the system temperature, which is essentially the temperature of the sky plus the temperature of the instrument. These belong to the observation:
[22]:
observation.tsky_amplitude.to("K")
[22]:
[23]:
observation.tsky_ref_freq
[23]:
[24]:
observation.spectral_index
[24]:
2.6
The thermal noise equation given by the equation is for \(P(k)\), but 21cmSense works with \(\Delta^2(k) = k^3P(k)/2\pi^2\), which thus depends on the scale, \(k\). Here, we’ll show the result without dividing by the time for which baselines occupy the cell:
[25]:
sensitivity.thermal_noise(
k_perp=0.1 * littleh / units.Mpc, k_par=0.1 * littleh / units.Mpc, trms=observation.Tsys
)
[25]:
5. Average over days¶
Since the sky repeats every day, we can average days together coherently. This increases the effective integration time per cell:
[26]:
observation = observation.clone(
n_days=180 # number of nights that a given point in the sky should be visible
)
[27]:
plt.imshow(observation.total_integration_time.value)
ax = plt.colorbar()
ax.set_label("Total Integration Time (s)")
finding redundancies: 100%|██████████| 319/319 [00:00<00:00, 2203.20ants/s]
gridding baselines: 100%|██████████| 3002/3002 [00:00<00:00, 9792.82baselines/s]
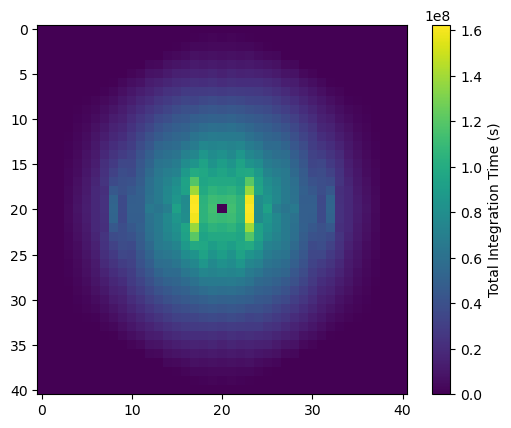
Similarly, we can calculate the thermal noise (in temperature units) for every cell (before the conversion of point 4 above):
[28]:
plt.imshow(np.log10(observation.Trms.value))
ax = plt.colorbar()
ax.set_label("Noise temperature per-cell log10(T/K)")
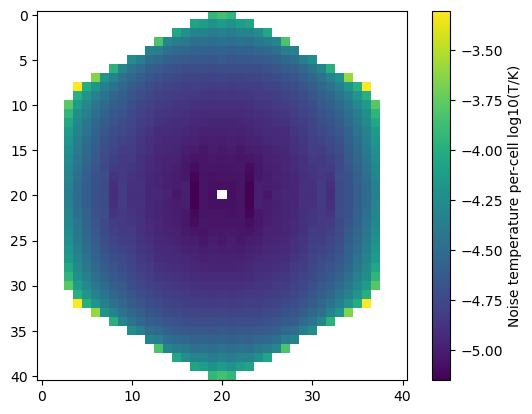
6. Associate Cosmological Scales¶
We have a grid of \(uv\eta\). We now convert these to \(k_\perp\) and \(k_{||}\) respectively. Note that these conversions depend slightly on redshift, but typically the range of redshifts under evaluation is so small that a linear conversion is appropriate:
[29]:
print(f"Minimum kparallel: {observation.kparallel.min():+.3f}")
print(f"Maximum kparallel: {observation.kparallel.max():+.3f}")
print(f"Delta kparallel : {observation.kparallel[1] - observation.kparallel[0]:+.3f}")
Minimum kparallel: -2.695 littleh / Mpc
Maximum kparallel: +2.628 littleh / Mpc
Delta kparallel : +0.067 littleh / Mpc
[30]:
kperp = observation.ugrid * p21s.conversions.dk_du(observation.redshift)
print(f"Minimum kperp: {kperp.min():+.3f}")
print(f"Maximum kperp: {kperp.max():+.3f}")
print(f"Delta kperp : {kperp[1] - kperp[0]:+.3f}")
Minimum kperp: -0.140 littleh / Mpc
Maximum kperp: +0.140 littleh / Mpc
Delta kperp : +0.007 littleh / Mpc
7. Add Cosmic Variance¶
Cosmic variance comes from the fact that measuring the power spectrum in a finite volume of the Universe doesn’t necessarily reveal the true underlying power spectrum of the Universe – it’s a random realization of the power. You can show that the uncertainty on the power is proportional to the power itself. Since it’s independent of the thermal noise, it just gets added in quadrature.
To obtain this quantity requires having some model of the power spectrum itself. In-built into 21cmSense is a fiducial 21cmFAST model from EOS2021:
[31]:
plt.plot(sensitivity.k1d, sensitivity.delta_squared)
plt.xscale("log")
plt.yscale("log")
plt.xlabel("Scale, k [h/Mpc]")
plt.ylabel(r"$\Delta^2(k)$ [mK^2]");
/home/steven/work/eor/21cmSense/py21cmsense/sensitivity.py:553: UserWarning: Extrapolating above the simulated theoretical k: 3.605864257424534 > 3.3903453170721027
return self.theory_model.delta_squared(self.observation.redshift, k)
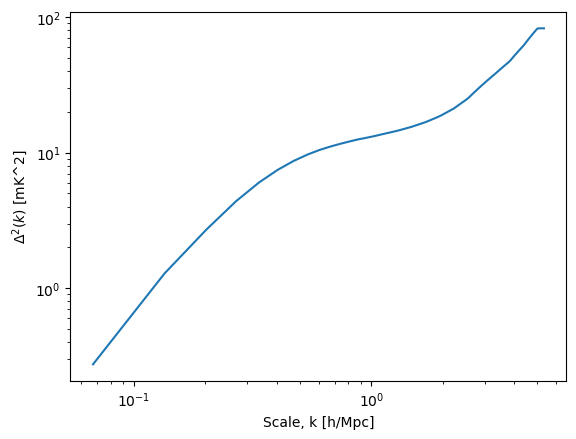
We’re not going to add it in right here, we’ll wait for the last step.
8. Add Everything Together¶
Now, there’s a few things we need to add together at this stage. What we have effectively is a thermal noise per cell of \(uv\eta\) (corresponding to 3D k-space), and a cosmic variance for each cell.
What we want in the end is the thermal noise in a bin of spherically-averaged \(k\). We’ll first do a cylindrical average, averaging in the \(\mathbf{k}_\perp\) plane:
[32]:
sense_2d = sensitivity.calculate_sensitivity_2d()
calculating 2D sensitivity: 100%|██████████| 561/561 [00:01<00:00, 432.41uv-bins/s]
[41]:
sensitivity.plot_sense_2d(sense_2d)
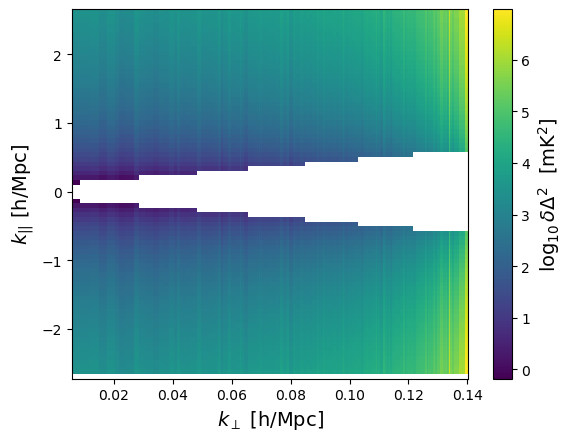
The big white part here is the “foreground wedge”, where we assume we’ll never take observations (the uncertainty there is infinite). We can modify its extent when creating the sensitivity:
[34]:
sensitivity = p21s.PowerSpectrum(observation=observation, foreground_model="optimistic")
[35]:
sense_2d_opt = sensitivity.calculate_sensitivity_2d()
calculating 2D sensitivity: 0%| | 0/561 [00:00<?, ?uv-bins/s]calculating 2D sensitivity: 100%|██████████| 561/561 [00:01<00:00, 420.83uv-bins/s]
[36]:
sensitivity.plot_sense_2d(sense_2d_opt)
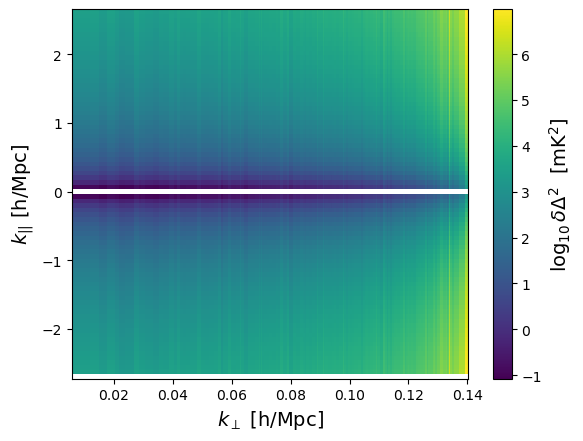
Finally, we average over circular shells in the 2D plot. We can do this for just thermal, just cosmic variance, or both:
[37]:
sense_1d_both = sensitivity.calculate_sensitivity_1d()
sense_1d_sample = sensitivity.calculate_sensitivity_1d(thermal=False)
sense_1d_thermal = sensitivity.calculate_sensitivity_1d(sample=False)
averaging to 1D: 100%|██████████| 153/153 [00:00<00:00, 172.42kperp-bins/s]
averaging to 1D: 100%|██████████| 153/153 [00:00<00:00, 178.46kperp-bins/s]
averaging to 1D: 100%|██████████| 153/153 [00:00<00:00, 175.81kperp-bins/s]
[38]:
sense_high = sensitivity.clone(
observation=observation.clone(
observatory=observation.observatory.clone(
beam=p21s.GaussianBeam(frequency=200 * units.MHz, dish_size=14 * units.m)
)
)
)
[39]:
p21s.config.PROGRESS = False
fix, ax = plt.subplots(
5, 5, sharex=True, sharey=True, figsize=(15, 15), gridspec_kw={"hspace": 0.05, "wspace": 0.05}
)
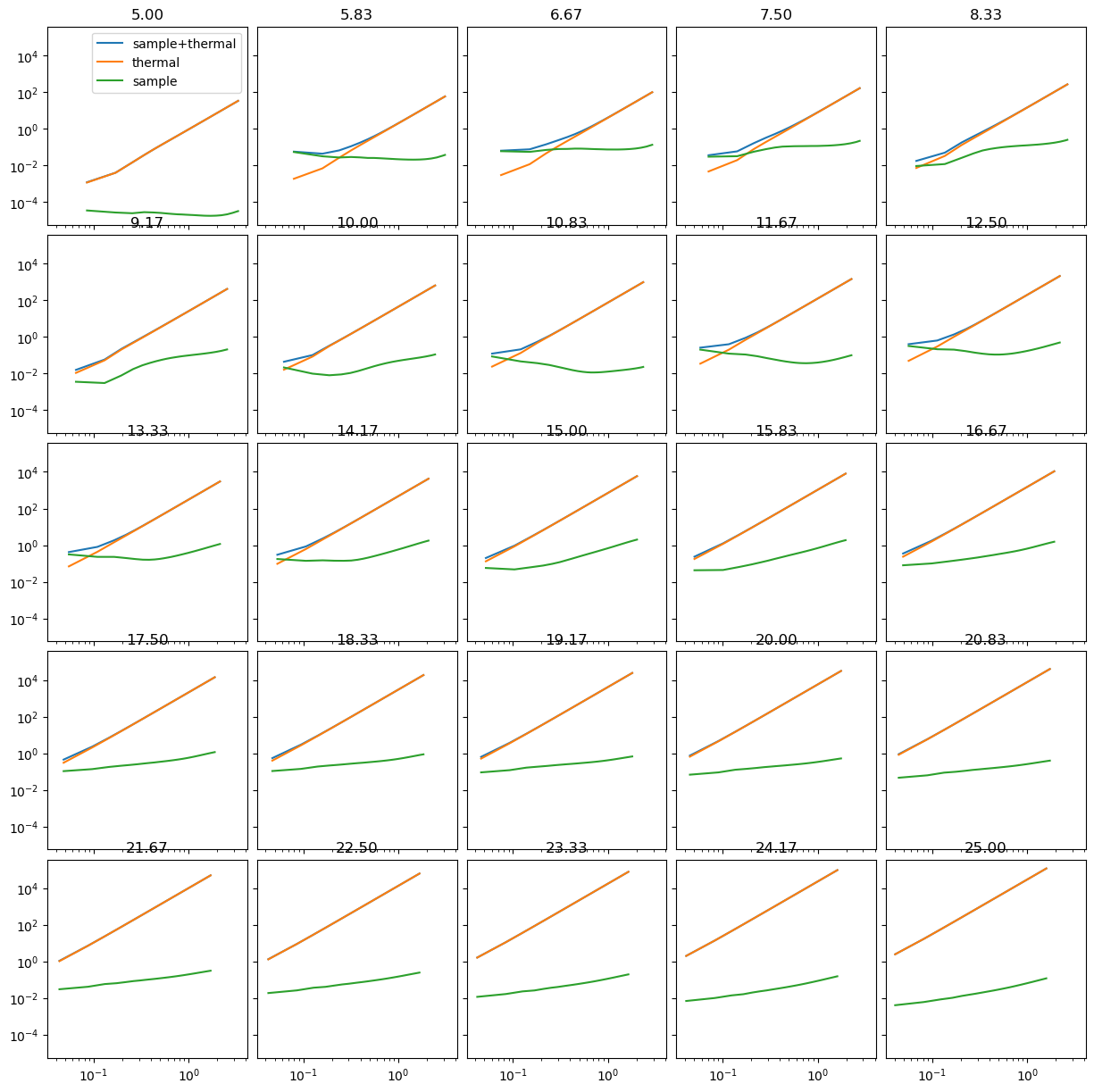
redshifts = np.linspace(5, 25, 25)
for i, z in enumerate(redshifts):
sense_high = sensitivity.clone(
observation=observation.clone(
observatory=observation.observatory.clone(
beam=p21s.GaussianBeam(frequency=1420 * units.MHz / (1 + z), dish_size=14 * units.m)
)
)
)
ax.flatten()[i].plot(
sense_high.k1d, sense_high.calculate_sensitivity_1d(), label="sample+thermal"
)
ax.flatten()[i].plot(
sense_high.k1d, sense_high.calculate_sensitivity_1d(sample=False), label="thermal"
)
ax.flatten()[i].plot(
sense_high.k1d, sense_high.calculate_sensitivity_1d(thermal=False), label="sample"
)
ax.flatten()[i].set_xscale("log")
ax.flatten()[i].set_yscale("log")
ax.flatten()[i].set_title(f"{z:.2f}")
ax[0, 0].legend();